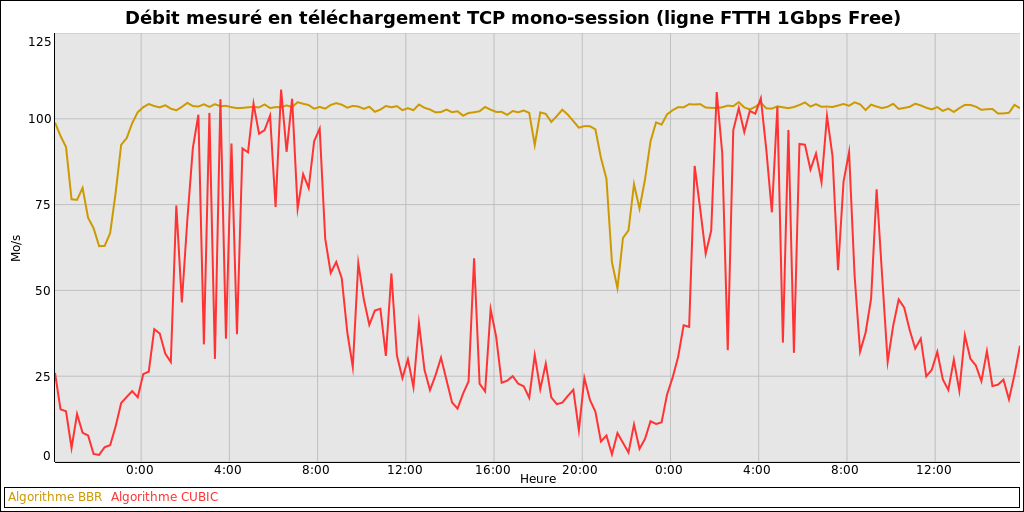
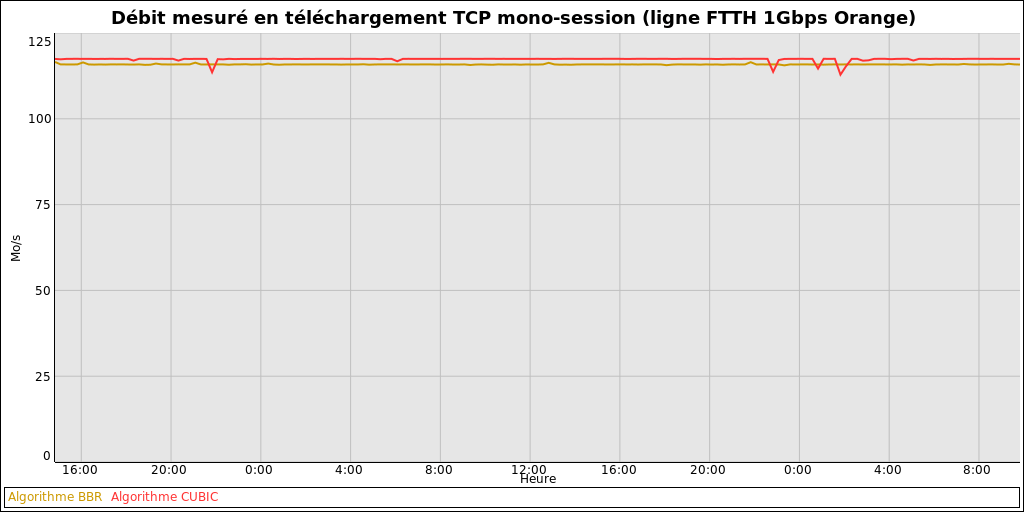
Voici un comparatif de débits descendants mono-connexion TCP BBR vs CUBIC, réalisé en utilisant exactement le même protocole de test sur deux connexions FTTH 1Gbps:
Protocole de test:
Toutes les 15 minutes, les 4 tests de débit suivants sont réalisés:
- 30 secondes de téléchargement TCP en BBR depuis l'AS 12876 (Scaleway)
- 30 secondes de téléchargement TCP en CUBIC depuis l'AS 12876 (Scaleway)
- 30 secondes de téléchargement TCP en BBR depuis l'AS 5410 (Bouygues Telecom)
- 30 secondes de téléchargement TCP en CUBIC depuis l'AS 5410 (Bouygues Telecom)
Pour chaque algo de congestion (BBR / CUBIC), seul le débit max entre les 2 AS testés est retenu pour tenter d'éliminer les éventuelles saturations extérieures au réseau du FAI.
La ligne Free était inutilisée au moment des tests.

