Et je suis à peu près certain que tout le monde utilise les memes ASIC, donc peu de difference sur le hard, c'est vraiment sur l'implementation logique qu'on va trouver des écarts.
Effectivement. Il y a des différences majeur dans l’implèmentation.
Premièrement Google se base sur des ASIC 16 x 40G et les gèrent indépendamment. CAD que un switch Centauri contient 4 asics mais que cela ne fait pas un switch de 64 x 40G, mais 4 switches de 16 x 40 G. C'est la mise en place de la topologie Clos.
Donc, chaque Centauri switch est une enclosure pour 4 switches de 16 x 40 G (ou 64 X 10G).
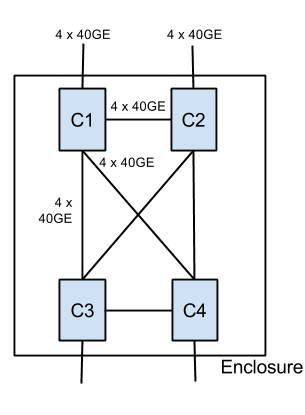
On voit aussi cela en essayant de comprendre le design des TORs. La seul chose qui est sure c'est que les TOR sont connectées a l'Aggregation (8 x middle blocks) via 2x10GE. Par ASIC. Soit 16 x 10GE = 4 x 40GE sur l'ASIC. Cela laisse 12 x 40 GE sur l'asic qui sont utilise pour connecter les 3 autres asic dans la même enclosure en mesh (voir l'image attachée - de moi).
Finalement, depuis le debut de l'initiative (il y a 10 ans) Google avait besoin de la gestion de mutlipaths qui n'existait pas.
En gros, chaque asic est gérée en fonction de sa position dans l'architecture global (par software) et permet de mettre en place des flows est/ouest a wire speed (pour la mise en place de reseau virtual non-basee sur les vlan definit par l'IEEE (Network Function Virtualization) ou autre features).

